ReaderBench - Automated Essay Grading
- Creator: UPB
- Publisher: Rage project
- Owner: Dascalu Mihai email
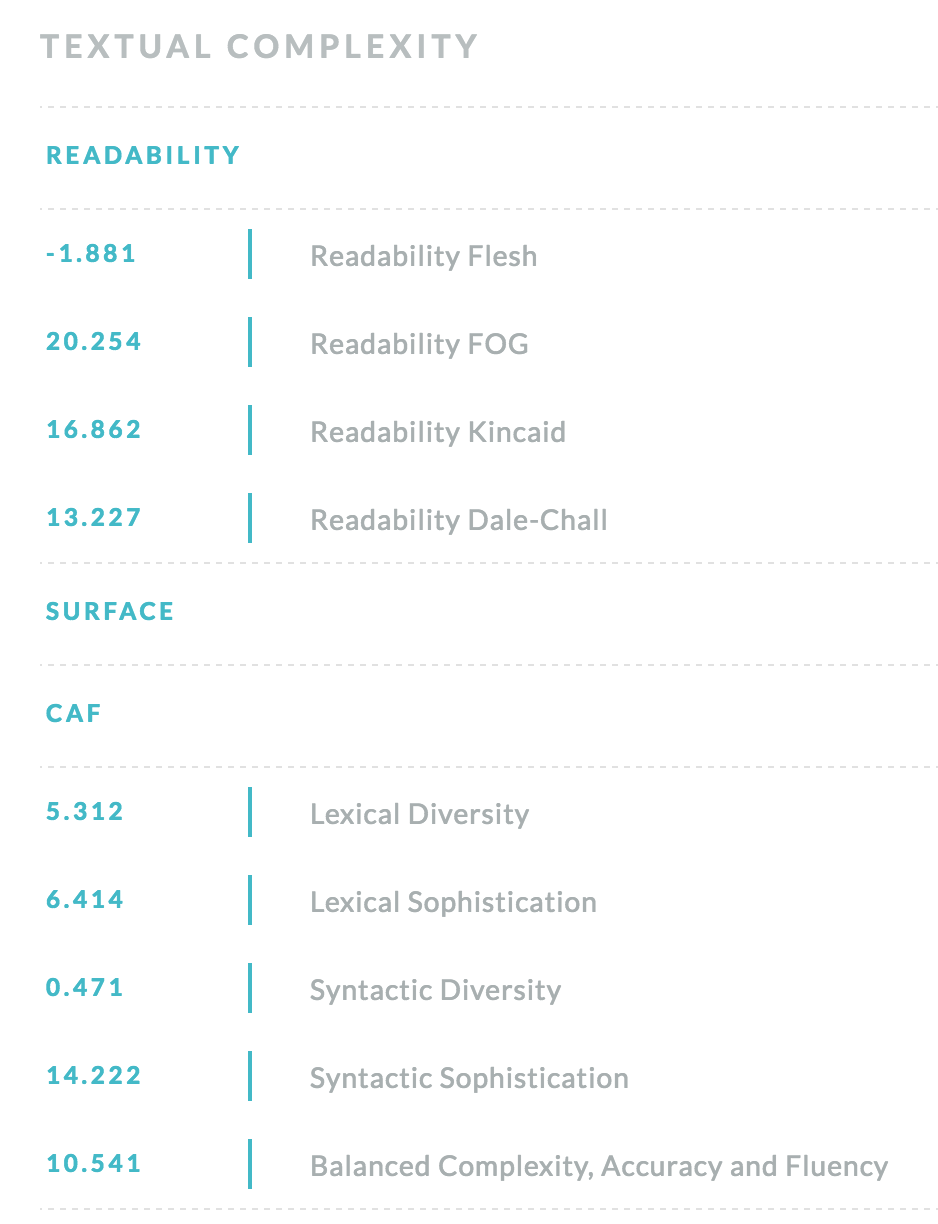
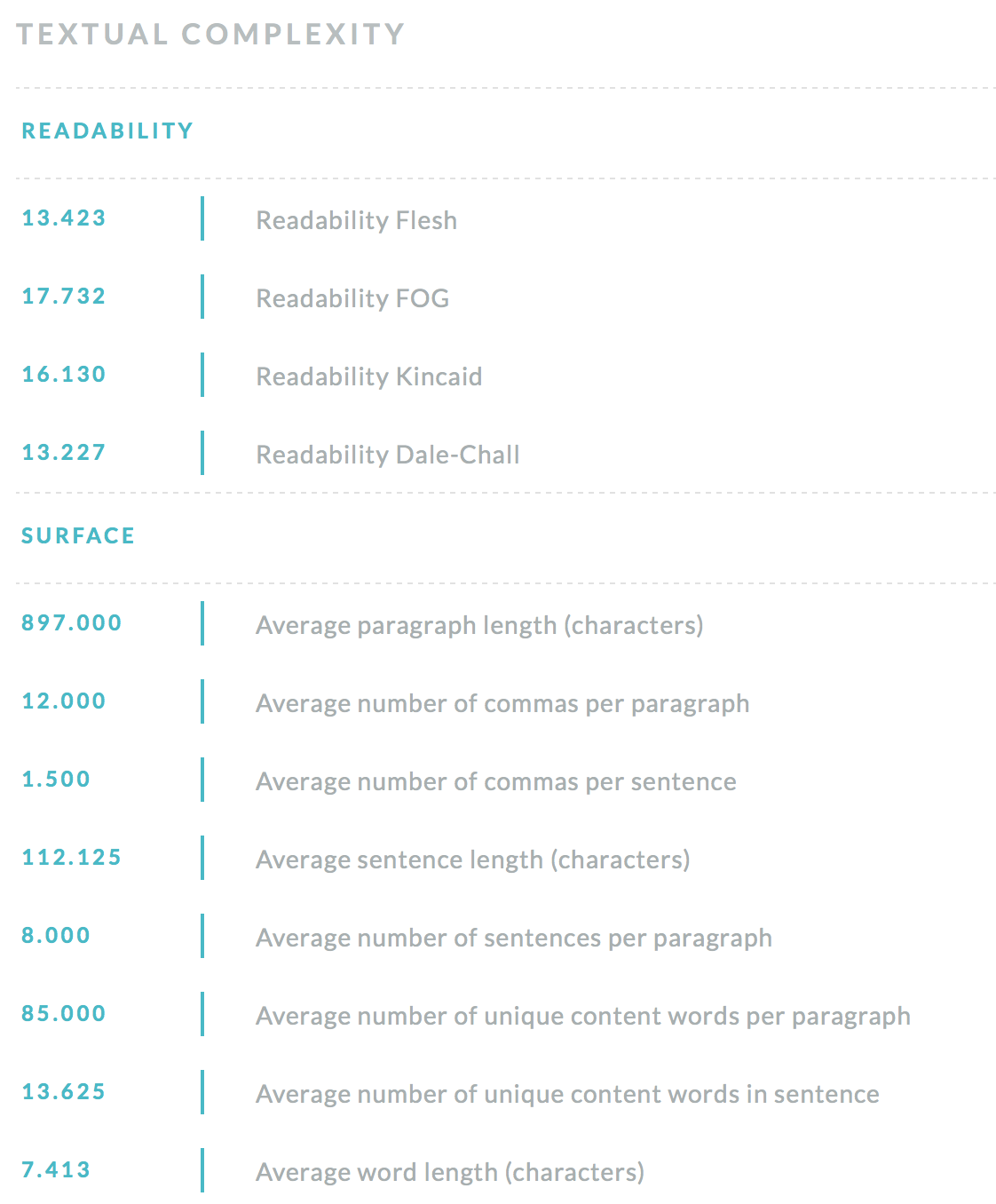
Determines a list of textual complexity indices of a text with their scores, grouped in categories.
Short non-technical description:
This asset provides a web service to detect textual complexity indices of a text.
The service provides a list of textual complexity indices with their scores, grouped in categories.
Technical description:
Automated evaluation of textual complexity represents a key focus for the linguistic research field as it emphasizes the evolution of technology’s facilitator role in educational processes. From a tutor perspective, the task of identifying accessible materials plays a crucial role in the learning process since inadequate texts, either too simple or too difficult, can cause learners to quickly lose interest.
Therefore, we have introduced a multi-dimensional analysis of textual complexity, covering a multitude of factors integrating classic readability formulas, surface metrics derived from automatic essay grading techniques, syntax indices, as well as semantics and discourse.
Essay analysis and grading plays a crucial role in the learning process because it is an indicator for a tutor about the progress of the student and for the latter because it provides a valuable feedback.
One of the main features of a well written essay is to have a complexity tailored to a specific destination. Therefore, we have introduced a multi-dimensional analysis of textual complexity, covering a multitude of factors integrating classic readability formulas, surface metrics derived from automatic essay grading techniques, syntax indices, as well as semantics and discourse that are afterwards combined through the use of specific supervised classifiers (e.g., Support Vector Machines, Discriminant Function Analysis). In the end, each factor can be correlated to learners’ comprehension traces, therefore creating a clearer perspective in terms of measurements impacting the perceived difficulty of a given text.
In a nutshell, the proposed evaluation model combines statistical factors and traditional readability metrics with information theory, specific information retrieval techniques, probabilistic parsers, Latent Semantic Analysis and Latent Dirichlet Allocation semantic models for best-matching all components of the analysis. This facilitates a wide range of educational scenarios covering: automated evaluation of summaries with regards to comprehension prediction, assessment of cover letters in terms of language adequacy, as well as potential recommendations for improving one’s writing style.
This asset provides a web service to detect textual complexity indices of a text via a REST API implemented with Spark and based on the ReaderBench framework that is written in Java and encompasses advanced multi-lingual text mining techniques, a full NLP processing pipeline and semantic models (WordNet or equivalent, LSA, LDA). The service provides a list of textual complexity indices with their values, grouped in categories.
Support levels: The component is available "as is" without warranties or conditions of any kind. Reported bugs will be fixed. Continued support for new versions of the OS and game engines. New features will be added according to the developer's roadmap. New features can be added upon request (requires a service contract).
Detailed description:
The ReaderBench framework can be either cloned from our GitLab Repository or simply used as deployment library.
The Repository contains three projects:
- The ReaderBench Core
- The ReaderBench Desktop Client
- The ReaderBench API
The ReaderBench Core can be accessed to explore the Natural Language Processing functionalities and operations performed by ReaderBench. You may either clone this project and explore its contents, or you can simply use it as a Maven dependency by cloning it from our Artifactory server.
The ReaderBench Desktop Client can be used to test ReaderBench functionalities with the help of a Java Swing interface. This project uses the ReaderBench Core, so you may use it as a guide into integrating ReaderBench in your projects.
The ReaderBench API can be used to explore how the ReaderBench Application Programming Interface works. Similar to the ReaderBench Desktop Client, you may discover how to integrate the ReaderBench Core into a project.
Language: English, French
Access URL: https://git.readerbench.com/ReaderBench/ReaderBench.git
Download: ReaderBench-Automated-Essay-Grading.zip
essay grading
semantic models
textual complexity


Source code:
Documentation:
- http://readerbench.com/docs/essay-grading/manual
- https://git.readerbench.com/ReaderBench/ReaderBench/blob/v3.0/README.md
- https://git.readerbench.com/ReaderBench/ReaderBench/wikis/home
- http://readerbench.com/docs/api
Setup files:
- http://readerbench.com/docs/essay-grading/sdd
- https://git.readerbench.com/ReaderBench/ReaderBench/wikis/how-to/how-to-install-and-run-readerbench
- https://owncloud.readerbench.com/index.php/s/w33mnCcpH1Bp1zs/download?path=/&files=README.txt
Test:
Game development environment: Other
Target platform: Other
Programming language: Java
Version: 3.0
Version notes: Stable version after major project split.
Development status: Completed
Commit URL: https://git.readerbench.com/ReaderBench/ReaderBench/tags/v3.0
Type: Apache 2.0 (Apache License 2.0)

